背景
路况在地图渲染时候,会针对不同的拥堵情况选择不同颜色。一般来讲,道路拥堵情况分为三个状态,畅通,拥堵,缓行,分别用绿色,黄色,红色来渲染。
我们面临的问题是,已知道路属性以及通行速度,需要对路况状态进行分类。解决方案是依据第三方路况提供的路况状态以及抓取的高德路况状态来训练一个三分类模型。
特征处理
应用的特征如下
| feature | description |
|---|---|
| speed | 路况速度 |
| maxspeed | 道路最大速度 |
| highway_level | 道路等级,共有17种可能,使用one-hot-encoding |
| lanes | 车道数 |
| oneway | 是否是单向路,使用one-hot-encoding |
路况状态使用 0-1-2 分别表示畅通-拥堵-缓行
处理好的特征使用\t分割的文本处理,最后一列代表路况状态。
模型训练
模型使用TensorFlow 提供的DNN分类器。代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146#-*- coding: utf-8 -*-
"""
File Name: traffic_status_classifier.py
Author: ce39906
mail: ce39906@163.com
Created Time: 2018-09-03 19:11:57
"""
import sys
import time
import numpy as np
import tensorflow as tf
FEATURES = [ "speed",
"maxspeed",
"level_1",
"level_2",
"level_3",
"level_4",
"level_5",
"level_6",
"level_7",
"level_8",
"level_9",
"level_10",
"level_11",
"level_12",
"level_13",
"level_14",
"level_15",
"level_16",
"level_17",
"lanes",
"oneway_0",
"oneway_1"]
def usage():
print "python %s ${train_data_file}" % (sys.argv[0])
def read_data(train_data_file):
xy_list = []
with open(train_data_file, 'r') as f:
for line in f:
line = line.strip('\n')
content = line.split('\t')
xy = [int(float(x)) for x in content]
xy_list.append(xy)
# 80% as train data, 20% as test data
train_xy = xy_list[ : int(len(xy_list) * 0.8)]
test_xy = xy_list[int(len(xy_list) * 0.8) : ]
train_x = [x[ : -1] for x in train_xy]
train_y = [x[-1] for x in train_xy]
test_x = [x[ : -1] for x in test_xy]
test_y = [x[-1] for x in test_xy]
return train_x, train_y, test_x, test_y
def list_2_tf_dataset(train_x, train_y, test_x, test_y):
train_x = np.array(train_x)
train_y_dataset = np.array(train_y)
test_x = np.array(test_x)
test_y_dataset = np.array(test_y)
train_x_cols = []
for col in train_x.T:
train_x_cols.append(col)
train_x_dataset = {}
for i in range(len(FEATURES)):
train_x_dataset[FEATURES[i]] = train_x_cols[i]
test_x_cols = []
for col in test_x.T:
test_x_cols.append(col)
test_x_dataset = {}
for i in range(len(FEATURES)):
test_x_dataset[FEATURES[i]] = test_x_cols[i]
return train_x_dataset, train_y_dataset, test_x_dataset, test_y_dataset
def train_input_fn(features, labels, batch_size):
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
# Shuffle, repeat, and batch the examples.
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
return dataset
def eval_input_fn(features, labels, batch_size):
if labels is None:
inputs = features
else:
inputs = (features, labels)
dataset = tf.data.Dataset.from_tensor_slices(inputs)
# batch the example
dataset = dataset.batch(batch_size)
return dataset
def main():
if len(sys.argv) != 2:
usage()
sys.exit()
batch_size = 100
steps = 10000
train_data_file = sys.argv[1]
# adapt to tensorflow format
train_x_list, train_y_list, test_x_list, test_y_list = read_data(train_data_file)
train_x, train_y, test_x, test_y = \
list_2_tf_dataset(train_x_list, train_y_list, test_x_list, test_y_list)
feature_columns = []
for key in train_x.keys():
feature_columns.append(tf.feature_column.numeric_column(key = key))
start_time = time.time()
classifier = tf.estimator.DNNClassifier(
feature_columns = feature_columns,
hidden_units = [10, 10],
n_classes = 3)
# train the model
classifier.train(
input_fn = lambda:train_input_fn(train_x, train_y, batch_size),
steps = steps)
end_time = time.time()
print 'Train DNN Classifier cost %fs.' %(end_time - start_time)
# evaluate the model
eval_result = classifier.evaluate(
input_fn = lambda:eval_input_fn(test_x, test_y, batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
if __name__ == '__main__':
main()
输出如下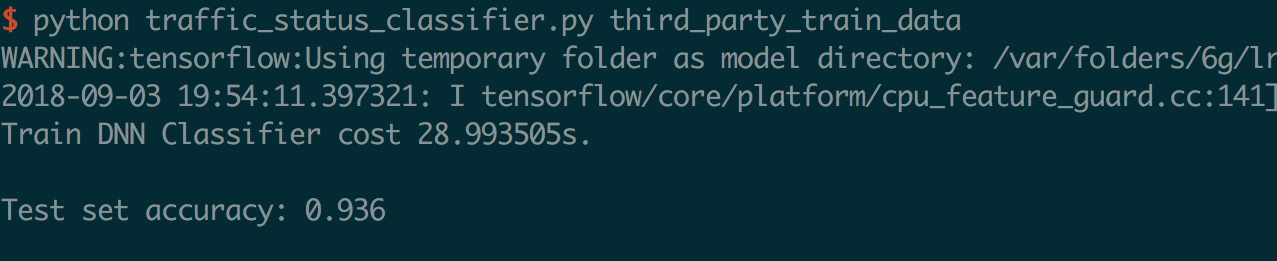
模型应用到C++工程
TODO

