背景
路况在地图渲染时候,会针对不同的拥堵情况选择不同颜色。一般来讲,道路拥堵情况分为三个状态,畅通,拥堵,缓行,分别用绿色,黄色,红色来渲染。
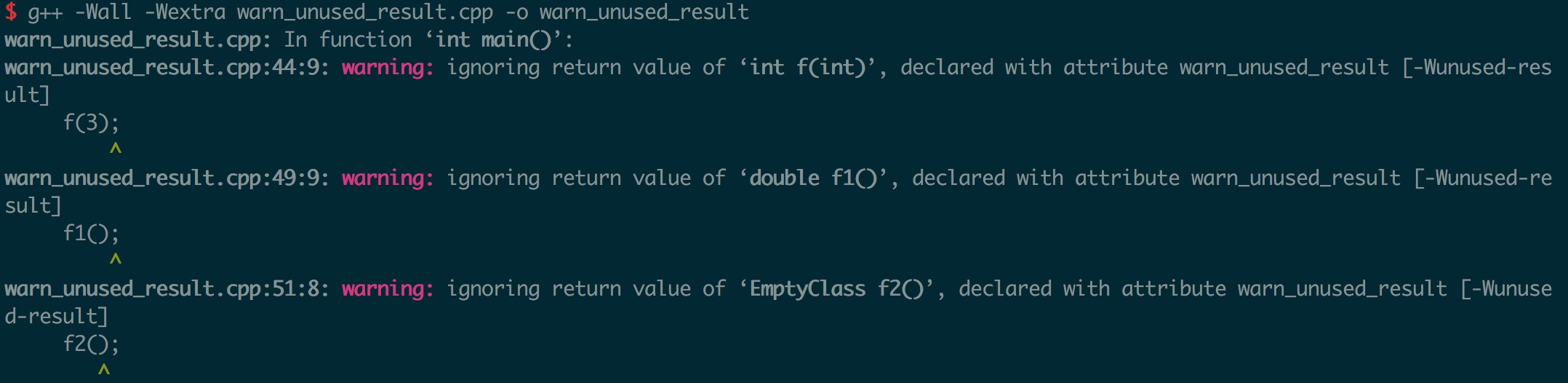
我们面临的问题是,已知道路属性以及通行速度,需要对路况状态进行分类。解决方案是依据第三方路况提供的路况状态以及抓取的高德路况状态来训练一个三分类模型。
特征处理
应用的特征如下
| feature | description |
|---|---|
| speed | 路况速度 |
| maxspeed | 道路最大速度 |
| highway_level | 道路等级,共有17种可能,使用one-hot-encoding |
| lanes | 车道数 |
| oneway | 是否是单向路,使用one-hot-encoding |
路况状态使用 0-1-2 分别表示畅通-拥堵-缓行
处理好的特征使用\t分割的文本处理,最后一列代表路况状态。